
Well hello there!
If you landed here by chance, I suggest you read Part 1 before continuing. It’s got some juicy bits!
As we saw in the previous article, probability is a measure of uncertainty. However, that article was limited to a discussion of discrete events or random variables i.e. picking a blue or red box, an orange or green ball etc. We now extend this notion to continuous variables such as banana weights, hut temperatures, pressures, amount of rainfall in the jungle etc.
Our first tool is the Cumulative Distribution Function!
Cumulative Distribution Functions
Continuous random variables can take on any value in the set of real numbers i.e. 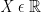
As a result, we need a function that squashes down the set of real numbers to the interval 0 and 1. That is where we define the Cumulative Distribution Function (CDF). For the purposes of this article a CDF of 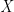
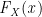
Any
![\mathit{F_X(x) \colon \mathbb{R} \mapsto [0, 1]}](https://s0.wp.com/latex.php?latex=%5Cmathit%7BF_X%28x%29+%5Ccolon+%5Cmathbb%7BR%7D+%5Cmapsto+%5B0%2C+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
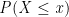
It is particularly important to note that the CDF gives the probability that a random variables is less than or equal to a specific value. Popular CDFs are presented in Figure 1 below.
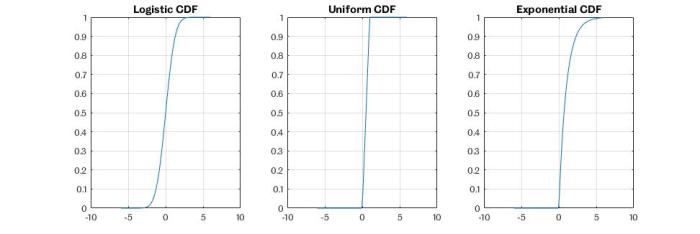
The Logistic Sigmoid is an important CDF as it represents a lot of natural processes in the universe. Other examples include the Exponential CDF or the Uniform CDF.
Probability Density Functions
Another, way of representing the CDF is through its derivative.
The derivative is called the Probability Density Function (PDF) and it represents our second tool for probability. For the purposes of this article a PDF of 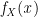
Any
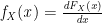

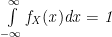
It is important to note that the PDF doesn’t give the probability directly. It’s value can go above 1. However, the integral of the PDF with respect to any value will be at most 1, and correspond to the CDF at that point.
PDFs only exists when the corresponding CDF is continuously differentiable everywhere! Basically, the CDF can’t have any sudden jumps. An example of a non-continuous function is the heavy-side step function.
Examples of popular PDFs are the Normal, Uniform and Exponential PDFs. These have all been produced by differentiating their respective CDFs! They are shown below in Figure 2.

The Gaussian PDF is extremely important. There is a well known theorem called the Central Limit Theorem which outlines its practicality. It says, if you collect enough data points, assuming they are all independent and identically distributed, the distribution of the averages will tend to look Gaussian! It’s pretty remarkable.
Figure 3 outlines this phenomenon. First, I took the average of varying lengths of data (5 – 10000 points), all generated from a Uniform distribution. I then plotted histograms of these averages. You can see that the result is pretty much Gaussian!

The MATLAB code I implemented is presented below. Run it and tweak the distributions. It works for any of them!
close all
clear all
clc
point = logspace(0.69,4,500);
mn = [];
for i=1:length(point)
data = rand(round(point(i)),1);
mn(i) = sqrt(length(data))*(mean(data)-0.5);
if i > 2
histfit(mn,25);
title(['No. Points: ' num2str(round(point(i)))])
grid on
end
end
Anyway, enough of that. We now know about PDFs and CDFs! Those are two very important concepts in probability.
Cogs of Probability: With Continuous Variables
This section borrows heavily from Part 1.
All of the good stuff we learnt from Part 1 can be used with PDFs and CDFs. So there is nothing new here. It’s just a bunch of equations that are quite analogous to their discrete equivalents.
The Sum Rule can be defined as:
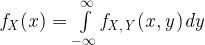
In this equation the value 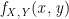
The Product Rule can be defined as:
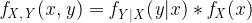
The value 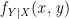
Finally, Bayes Theorem can be fully represented as:
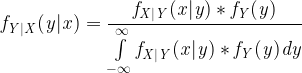
These equations might look intimidating, but they are actually very straightforward. A comparison with the equations in Part 1 will emphasise their definitions.
An important note is that these quantities, unlike in Part 1, are now functions. That is what sets them apart and makes them vastly more powerful!
Expectation: What do you tend to?
Expectation is another term for expected value. Conceptually, it is the average outcome of an experiment, if you run the experiment a large number of times. In terms of probability it is simply a weighted average of the outcomes of an experiment.
This works because probability is defined as event occurrences over an infinite number of observations! Therefore, if you have a PDF, you don’t need to run an infinite number of experiments; just use your PDF to figure out what your result will be, on average.
Assume you have a random variable
![\mathit{\mathbb{E}[X] = \int\limits_{-\infty}^\infty x*f_{X}(x)dx}](https://s0.wp.com/latex.php?latex=%5Cmathit%7B%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cint%5Climits_%7B-%5Cinfty%7D%5E%5Cinfty+x%2Af_%7BX%7D%28x%29dx%7D&bg=ffffff&fg=000000&s=1&c=20201002)
The experiment in this case is observing 
Expectation is a description of location in statistics. Another very common descriptor is variance and can be defined as:
![\mathit{var[X] = \mathbb{E}[X^2] - \mathbb{E}[X]}](https://s0.wp.com/latex.php?latex=%5Cmathit%7Bvar%5BX%5D+%3D+%5Cmathbb%7BE%7D%5BX%5E2%5D+-+%5Cmathbb%7BE%7D%5BX%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
The variance of a random variable describes how spread the various points are from the average value.
What’s the point? Why go through all of this?
Good lord! That was a lot of probability. Well done for sticking with it though. It’s a tough concept to visualise, which makes it tough to understand. I wrote this whole thing and I’m still unsure about some stuff. But anyway, let me motivate the why!
When we run experiments, the results are always corrupted by noise. Noise creeps in from everywhere; sensors, human error, etc. We hate noise. Noise means that we can never be completely sure of our answer. A probabilistic framework allows us to capture all this uncertainty in a numerical way!
In a field like ML, where the focus is data, noise is an implicit characteristic. Understanding probability allows you to wield the power of Machine Learning in the right way. Understanding the potential of the tools you’ve been given, is a very powerful thing.
As always, thanks for having a read! Please comment and let me know if I’ve missed anything out or if anything could have been made clearer.
Happy swinging!
Further Resources
Probability: For a more mathematical and rigorous treatment of the concepts in Parts 1&2, I’ve found this document from the Standford CS229 ML course extremely helpful. It does motivate things from the perspective of sets followed by random variables, but It’s not too difficult.
Probability Theory: A particularly good blog on Probability and Statistics is by Dan Ma. You can find it here. A quick search for things to do with expectation, bayes theorem etc, will give you quite a lot of information.
Expected Value: Go over the “Definition” section over here. It goes through a numerical example Expectation.
